Introduction
One of IDA Pro’s most important features is that it allows us to interactively modify the disassembly – hence, the I in IDA. This includes renaming of function names, variable names, and names of addresses. IDA Pro refers to these names as identifiers and enforces a certain naming scheme on them. After working with IDA Pro for a couple of weeks most people develop a good understanding of valid names and what to avoid when renaming identifiers. However, I wanted to know how IDA Pro checks identifiers and describe my findings in this blog post. In addition to this, I discuss the character encoding used for comments in IDA Pro. Adding comments to a disassembled program is another useful feature many reverse engineers take advantage of. While users normally don’t have to worry about the comment encoding this information can be handy in certain situations – especially when dealing with comments in IDAPython scripts.
IDA Pro’s naming scheme for identifiers
I am sure most reverse engineers have tried to rename a function name or a stack frame variable in IDA Pro and were confronted with one of the following error messages:
- “Can not rename structure member as ‘1st_argument'” (Figure 1)
- “4EEDE0: can’t rename byte as ‘GetCommand#’ because it contains a bad character ‘#’.” (Figure 2).
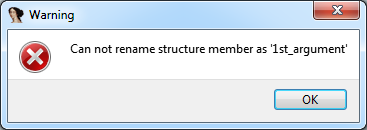
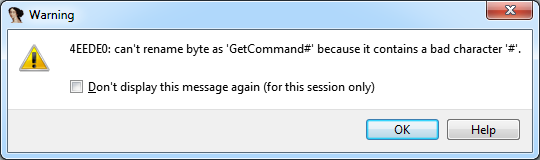
These error messages indicate that the identifier names you thought so hard of do not confer with IDA Pro’s naming scheme. They are also a great starting point for an analysis of IDA Pro’s actual implementation. The following analysis was performed with and on IDA Pro 6.95.160808 (32-bit).
As a side note, the program’s End User License Agreement explicitly allows to reverse engineer IDA Pro.
The first error message string shown in Figure 1 is referenced once in idaq.exe. The error message is displayed if a name already is defined locally or if the function set_member_name fails (see Figure 3).
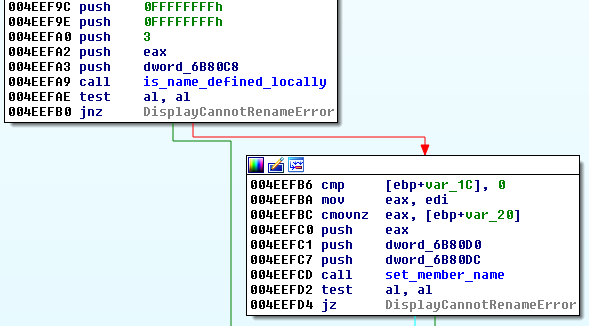
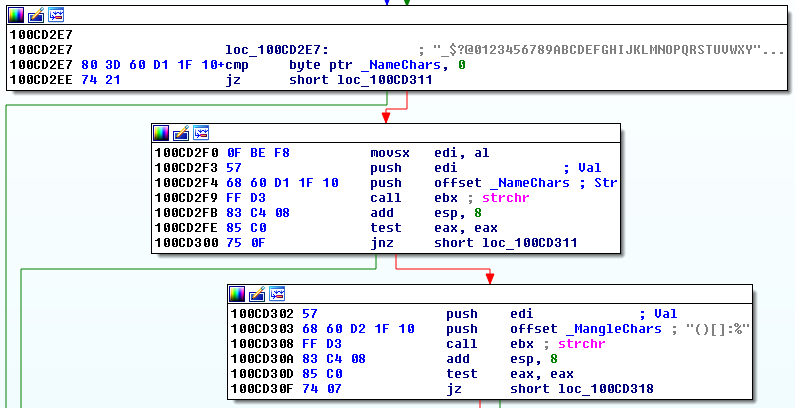
set_member_name is imported from ida.wll. In ida.wll the first call in set_member_name is made to the function isident. isident contains the checks enforcing the naming scheme of valid identifiers. Figure 4 shows parts of the isident function responsible for verifying that all characters in a string stem from one of two fixed character sets. The checks performed can be summarized as follows:
- The string cannot be a register name used in the program (but you can use the name rax in a 32-bit program, for example)
- The first character cannot be a digit
- The name can only consist of the characters from the following character sets:
- NameChars: _$?@0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxy
- MangleChars: ()[]:%
These constraints are used to check the identifier names of many objects, including:
- Structures
- Enums
- Register names
- Functions (locations)
Before renaming a function name (a location) IDA Pro also checks that the identifier does not start with a prefix reserved for dummy names. Dummy names are names that IDA Pro generates automatically such as sub_, loc_, or byte_. They are listed under “Names Representation” in the help files.
During this research I discovered that IDA Pro’s help files also list parts of the naming scheme for identifiers under the topic “Cannot rename a location”. Always read the documentation…
IDA Pro’s character encoding for comments
While the naming scheme enforces a limited character set for identifiers, there are no restrictions on text that can be added as comments. The only limitations that arise stem from the character encoding used for comments. For example, you can’t use Unicode characters “Skull and Crossbones” (☠, U+2620) or “Pile of Poo” (?, U+1F4A9) in your comments.
I first stumbled across character encoding issues when adding comments to an IDB file using an IDAPython script. The comments I wanted to add were stored in a JSON file containing UTF-8 encoded data. Figure 5 shows an example script that I use for demonstration purposes. The script adds one German and one (probably) Spanish comment to an IDB file starting at the current cursor address. Both strings are UTF-8 encoded and contain non-ASCII characters.
# -*- coding: utf-8 -*-
from __future__ import print_function
from idc import ScreenEA, NextHead, MakeComm, Comment
def main():
""" Add and print comments starting at current cursor address. """
ea = ScreenEA()
next_ea = NextHead(ea)
# add comments
comment0 = "Gänsefüßchen nicht vergessen."
comment1 = "¡Un sueño super grande!"
MakeComm(ea, comment0)
MakeComm(next_ea, comment1)
# retrieve comments
print(Comment(ea))
print(Comment(next_ea))
if __name__ == '__main__':
main()
Figure 5: Example script for adding and retrieving comments to an IDB fileThe following screenshots illustrate how the special characters cause comment havoc. Figure 6 shows the added comments. Figure 7 shows the retrieved comment output.
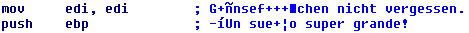

This time I checked the documentation right away, but could not find any information on the encoding IDA Pro uses for comments. An online search did not provide useful information either. So, I sent an email to Hex-Rays’ support and asked about this. Within minutes Ilfak responded that “On Windows IDA uses the system OEM encoding and on Unix IDA uses simple ASCII without performing any conversions”.
With this information we can now encode comments correctly before adding them. On Windows you can display the active code page (CP) number using the chcp command. My system uses code page (CP) 437. Figure 8 shows how the UTF-8 strings are decoded first and then encoded using the “cp437” encoding.
# -*- coding: utf-8 -*-
from __future__ import print_function
from idc import ScreenEA, NextHead, MakeComm, Comment
def encode(s):
""" Return CP437 encoded string from UTF-8 encoded string. """
return s.decode("utf-8").encode("cp437")
def main():
""" Add and print comments starting at current cursor address. """
ea = ScreenEA()
next_ea = NextHead(ea)
# add comments
comment0 = "Gänsefüßchen nicht vergessen."
comment1 = "¡Un sueño super grande!"
MakeComm(ea, encode(comment0))
MakeComm(next_ea, encode(comment1))
# retrieve comments
print(Comment(ea))
print(Comment(next_ea))
if __name__ == '__main__':
main()
Figure 8: Encoding comments before adding themFigure 9 shows that the comments are added correctly now. However, the right encoding is not applied when retrieving them (see Figure 10).

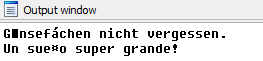
Figure 11 shows the final script applying the proper encoding and decoding when working with comments. Figure 12 shows that the retrieved comments are encoded correctly now.
# -*- coding: utf-8 -*-
from __future__ import print_function
from idc import ScreenEA, NextHead, MakeComm, Comment
def encode(s):
""" Return CP437 encoded string from UTF-8 encoded string. """
return s.decode("utf-8").encode("cp437")
def decode(s):
""" Return CP437 decoded string. """
return s.decode("cp437")
def main():
""" Add and print comments starting at current cursor address. """
ea = ScreenEA()
next_ea = NextHead(ea)
# add comments
comment0 = "Gänsefüßchen nicht vergessen."
comment1 = "¡Un sueño super grande!"
MakeComm(ea, encode(comment0))
MakeComm(next_ea, encode(comment1))
# retrieve comments
print(decode(Comment(ea)))
print(decode(Comment(next_ea)))
if __name__ == '__main__':
main()
Figure 11: Final script applying proper comment encoding and decoding
While this might not seem too bad, things can get more complicated when you are dealing with multiple systems and don’t know which code page each system uses. How do you make sure you achieve consistent results among those machines? And how do you handle different operating systems? As Ilfak said, on Unix systems IDA Pro encodes comments using ASCII.
With this in mind, I’ve decided to only use ASCII encoding when adding comments or extracting them in IDAPython scripts that potentially run on various systems. All relevant code pages should include the respective ASCII codes. Figure 13 shows how I modified the demo script for consistency among different systems using ASCII encoding.
# -*- coding: utf-8 -*-
from __future__ import print_function
from idc import ScreenEA, NextHead, MakeComm, Comment
def encode(s):
""" Return ASCII string from UTF-8 encoded string replacing characters that can't be encoded with replacement character '?'. """
return s.decode("utf-8").encode("ascii", errors="replace")
def decode(s):
""" Return CP437 decoded string. """
return s.decode("ascii", errors="replace")
def main():
""" Add and print comments starting at current cursor address. """
ea = ScreenEA()
next_ea = NextHead(ea)
# add comments
comment0 = "Gänsefüßchen nicht vergessen."
comment1 = "¡Un sueño super grande!"
MakeComm(ea, encode(comment0))
MakeComm(next_ea, encode(comment1))
# retrieve comments
print(decode(Comment(ea)))
print(decode(Comment(next_ea)))
if __name__ == '__main__':
main()
Figure 13: Script using ASCII encoding replacing non-ASCII charactersFigure 14 and Figure 15 show the resulting comments and the retrieved output after running this script.
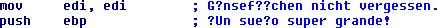
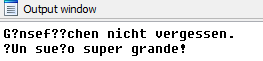
Passing errors=”replace” to the encode function replaces all characters that cannot be ASCII encoded with the replacement character ‘?’. Alternatively, you could use errors=”ignore” which removes all non-ASCII characters. I prefer “replace” because it better indicates that a character substitution occurred. Regardless of the encoding you use, the errors option is useful when your source strings contain characters that cannot be represented in the target encoding. In these cases the default option, errors=”strict”, results in a UnicodeEncodeError exception.
When dealing with English language comments this approach works almost seamlessly. An optional pre-processing step of the input data can additionally translate certain characters to equivalent ASCII codes. For example, the Unicode characters “en dash” (–, U+2013) and “em dash” (—, U+2014) can be translated to a regular ASCII dash (-, 0x2D).
I hope this information is useful to you. Please let me know if you have any questions or concerns. Either in the comment section below or via Contact.